Under What Circumstances Is the Definitional Formula Easy to Use
Psychology 240 Lectures
Chapter 4
Statistics one
Illinois State University
J. Cooper Cutting
Fall 1998, Section 04
A Kickoff Course for Students of Psychology and Education, 4th Edition. New York: West Publishing.
So far we've discussed two of the 3 characteristics used to depict distributions, now we need to discuss the remaining - variability. Discover in our distributions that not every score is the same, e.g., non everybody gets the same score on the exam. So what we need to do is draw the varied results, rougly to describe the width of the distribution.
- Variability provides a quantitiative measure of the degree to which scores in a distribution are spread out or clustered together.
In other words variablility refers to the caste of "differentness" of the scores in the distribution. High variability means that the scores differ past a lot, while low variability means that the scores are all similar ("homogeneousness").
The simplest measure of variability is the range, which nosotros've already mentioned in our before discussions.
- - The range is the divergence between the upper real limit of the largest (maximum) Ten value and the lower existent limit of the smallest (minimum) Ten value.
So look at your frequency distribution table, observe the highest and lowest scores and subtract the lowest from the highest (notation, if continuous must consider the existent limits).
__X f cf c% 10 2 25 100 9 viii 23 92 8 4 15 60 7 six eleven 44 6 4 v 20 5 1 i 4 | if X is discrete then:
if X is continuous and then:
|
- there are some drawbacks of using the range as the description of the variability of a distribution
- - the statistic is based solely on the two virtually extream values in the distribution, thus it doesn't capture all of the members of the distribution.
So think back to percentiles. 50%tile equals the point at which exactly half the distribution exists on one side and the other half on the other side.
- - Considering the same logic, what does the 25%tile represent? - The 75%?
- - So using the 25th, 50th, & 75%tiles we tin can break the distribution into 4 quarters, or quartiles
_X f % c% 7 four 12.v 100 6 4 12.v 87.five 5 4 12.5 75 iv 8 25 62.5 iii four 12.5 37.v ii four 12.5 25 1 4 12.5 12.5 | 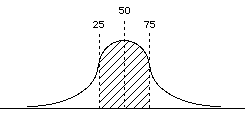 |
Then for the above distribution (assume that it is a continuous variable)
- median = Q2 = 4.0 -> using interpolation (notice exactly halfway between 62.v & 37.5)
25%tile = Q1 = 2.five -> the upper existent limit for the interval 2
75%tile = Q3 = 5.5 -> the upper real limit for the interval 5
Note that the interquartile range is often transformed into the semi-interquartile range which is 0.v of the interquartile range.
SIQR = (Q3 - Q1) 2So for our example the semi-interquartile range is (three.0)(0.5) = ane.five
So the interquartile range focusses on the centre half of all of the scores in the distribution. Thus it is more representative of the distribution equally a whole compared to the range and extreme scores (i.due east., outliers) will non influence the mensurate (sometimes refered to as being robust). Nonetheless, this nonetheless means that 1/two of the scores in the distribution are not represented in the measure.
The standard difference is the most pop and most important mensurate of variability. It takes into business relationship all of the individuals in the distribution.
In essence, the standard deviation measures how far off all of the individuals in the distribution are from a standard, where that standard is the mean of the distribution.
- We will begin by discussion the standard deviation parameter, that is the standard departure of the population. Then nosotros will discuss the standard deviation statistic (for the sample). They are closely related descriptive statistics, but they accept some important differences.
So to go a measure out of the deviation we need to decrease the population mean from every individual in our distribution.
- 10 - m = deviation score
- - if the score is a value above the hateful the deviation score volition be positive - if the score is a value below the mean the deviation score will be negative
Example: consider the following information set: the population of heights (in inches) for the class
69, 67, 72, 74, 63, 67, 64, 61, 69, 65, 70, 60, 75, 73, 63, 63, 69, 65, 64, 69, 65
hateful = m = 67
S (10 - g) = (69 - 67) + (67 - 67) + .... + (65 - 67) = ?
= 2+ 0 + 5 + vii + -iv + 0 + -3 + -half dozen + ii + -2 + iii + -7 + 8 + half dozen + -four + -4 + ii + -two + -3 + 2 + -ii
= 0
Find that if y'all add together up all of the deviations they should/must equal 0. Recall about it at a conceptual level. What you are doing is taking i side of the distribution and making it positive, and the other side negative and calculation them together. They should cancel each other out.
So what we accept to do is get rid of the negative signs. Nosotros do this by squaring the deviations and then taking the foursquare root of the sum of the squared deviations.
Sum of Squares = SS = S (Ten - chiliad)ii = (69 - 67) 2 + (67 - 67) ii + .... + (65 - 67) 2 =
SS = 4+ 0 + 25 + 49 + sixteen + 0 + 9 + 36 + 4 + 4 + ix +49 + 64 + 36 + sixteen + sixteen + 4 + iv + ix + iv + 4
SS = 362
The equation that we just used (SS = Due south (10 - g)2) is refered to as the definitional formula for the Sum of Squares. Yet, there is another way to compute the SS, refered to every bit the computational formula. The two equations are mathematically equivalent, however sometimes one is easier to utilise than the other. The reward of the computational formula is that it works with the Ten values directly.
The computational formula for SS is:
SS = SouthwardXii - (SX) 2 N
So for our example:
SS = [(69)two + (67)2 + ..... + (69)2 + (65)two] - (69 + 67 + ... + 69 + 65) 2 21 = 94631 - (1407) 2= 94631 - 94269 = 362 21
At present we have the sum of squares (SS), but to become the Population Variance which is simply the average of the squared deviations (we want the population variance non merely the SS, considering the SS depends on the number of individuals in the population, so we desire the mean). So to get the mean, we need to divide by the number of individuals in the population.
- Population variance = s 2 = SS/North
- standard divergence = sqroot(variance) = sqroot(SS/North)
s = sqroot(south)
- southward 2 = 362 / 21 = 17.24
due south = sqroot (17.ii) = 4.fifteen
To review:
- step 1: compute the SS
- - either by using definitional formula or the computational formula
- - take the average of the squared deviations
- divide the SS by the North
- - take the square root of the variance
- - the computations are pretty much the same here
- - different note:
- south = sample standard deviation
apply
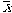 instead of m in the computaion of SS
instead of m in the computaion of SS - need to suit the ciphering to tak into business relationship that a sample will typically be less variable than the respective population.
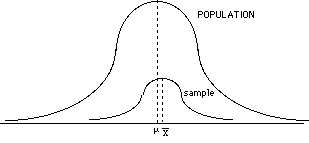
- if you take a good, representative sample, then your sample and population means should exist very similar, and the overall shape of the two distributions should be like. However, detect that the variability of the sample is smaller than the variability of the population.
- to account for this the sample variance is divided by n - 1 rather than simply n
sample variance = s2 = __SS _ n - ane
- and the same is truthful for sample standard difference
- sample standard divergence = southward = sqroot(SS/(n - 1))
So what nosotros're doing when we subtract 1 from n is using degrees of freedom to adjust our sample deviations to make an unbiased interpretation of the population values.
What are degrees of freedom? Think of information technology this way. You know what the sample mean is ahead of time (you've got to to figure out the deviations). So you tin can vary all just i item in the distribution. But the last item is fixed. There will be only 1 value for that item to brand the mean equal what it does. And so north - ane means all the values but one can vary.
Example:
- suppose that yous know that the mean of your sample = 5
- if your first 4 items are:
- v, 4, 6, ii then what must the terminal number be?
5 + four + 6 + ii + X = 25
there volition exist only ane value of 10 that'll make this work. Ten = 8
Okay, and then allow's practice an example of calculating the standard deviation of a sample
- data: ane, two, 3, 4, 4, five, 6, seven
footstep one: compute the SS
- SS = S (10 -
)2 = (1 - 4)2 + (two - 4)2 + (3 - 4)2 + (4 - 4)2 + (4 - iv)2 + (5 - four)2 + (6 - 4)2 + (7 - 4)2
= nine + 4 + 1 + 0 + 0 + 1 + iv + 9 = 28
-- OR --
You can nonetheless use the computational formula to become SS
SS = SX2 - (S X) two N = (1+4+9+16+sixteen+25+36+49) - (1+2+three+iv+four+5+6+7) 8 = 156 - 128 = 28.0step 2: determine the variance of the sample (retrieve it is a sample, and so we need to have this into account)
sample variance = sii = _SS_ n - anefootstep 3: determine the standard divergence of the sample= 28/(8-ane) = 28/seven = 4.0
- standard deviation = sqroot(SS/(n - 1))
- = sqroot(28/(8 - 1)
= sqroot iv.0 = 2.0
- 1) Adding a constant to each score in the distribution will not change the standard difference.
- ii) Multiplying each score by a constant causes the stardard deviation to be multiplied past the aforementioned constant.
Comparison Measures of Variability
- - Extreme scores: range is most afflicted, IQR is least affected
- Sample size: range tends to increase as n increases, IQR & south do not
- The range does not take stable values when you repeatedly sample from the aforementioned population, but the IQR & S are stable and tend not to fluctuate.
- With open-ended distributions, ane cannot even compute the range or S, so the IQR (or SIQR) is the only option
Source: https://psychology.illinoisstate.edu/jccutti/psych240/chpt4.html
0 Response to "Under What Circumstances Is the Definitional Formula Easy to Use"
Post a Comment